TCP协议中有长连接和短连接之分。短连接环境下,数据交互完毕后,主动释放连接;
双方建立交互的连接,但是并不是一直存在数据交互,有些连接会在数据交互完毕后,主动释放连接,而有些不会,那么在长时间无数据交互的时间段内,交互双方都有可能出现掉电、死机、异常重启,还是中间路由网络无故断开、NAT超时等各种意外。
当这些意外发生之后,这些TCP连接并未来得及正常释放,那么,连接的另一方并不知道对端的情况,它会一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,为了解决这个问题,在传输层可以利用TCP的保活报文来实现,这就有了TCP的Keepalive(保活探测)机制。
Tcp Keepalive存在的作用
探测连接的对端是否存活
在应用交互的过程中,可能存在以下几种情况:
- 客户端或服务端意外断电,死机,崩溃,重启。
- 中间网络已经中断,而客户端与服务器并不知道。
利用保活探测功能,可以探知这种对端的意外情况,从而保证在意外发生时,可以释放半打开的TCP、
连接。
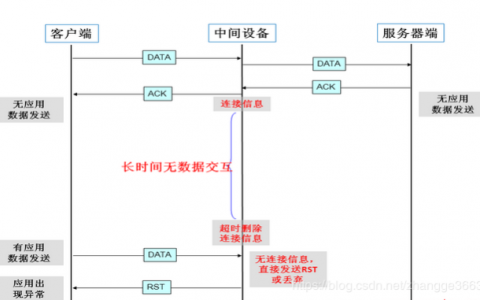
防止中间设备因超时删除连接相关的连接表
中间设备如防火墙等,会为经过它的数据报文建立相关的连接信息表,并未其设置一个超时时间的定时器,如果超出预定时间,某连接无任何报文交互的话,中间设备会将该连接信息从表中删除,在删除后,再有应用报文过来时,中间设备将丢弃该报文,从而导致应用出现异常,这个交互的过程大致如下图所示:

这种情况在有防火墙的应用环境下非常常见,这会给某些长时间无数据交互但是又要长时间维持连接的应用(如数据库)带来很大的影响,为了解决这个问题,应用本身或TCP可以通过保活报文来维持中间设备中该连接的信息,(也可以在中间设备上开启长连接属性或调高连接表的释放时间来解决。
常见应用故障场景:
某财务应用,在客户端需要填写大量的表单数据,在客户端与服务器端建立TCP连接后,客户端终端使用者将花费几分钟甚至几十分钟填写表单相关信息,终端使用者终于填好表单所需信息后,点击“提交”按钮,结果,这个时候由于中间设备早已经将这个TCP连接从连接表中删除了,其将直接丢弃这个报文或者给客户端发送RST报文,应用故障产生,这将导致客户端终端使用者所有的工作将需要重新来过,给使用者带来极大的不便和损失。
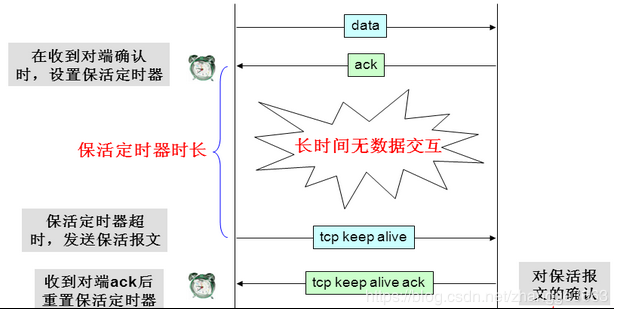
TCP保活报文交互过程
TCP保活的交互过程大致如下图所示:
TCP保活可能带来的问题:
- 中间设备因大量保活连接,导致其连接表满,网关设备由于保活问题,导致其连接表满,无法新建连接(XX局网闸故障案例)或性能下降严重
- 正常连接被释放
当连接一端在发送保活探测报文时,中间网络正好由于各种异常(如链路中断、中间设备重启等)而无法将保活探测报文正确转发至对端时,可能会导致探测的一方释放本来正常的连接,但是这种可能情况发生的概率较小,
另外,一般也可以增加保活探测报文发生的次数来减少这种情况发生的概率和影响。
TCP Keepalive协议解读
下面协议解读,基于 RFC1122#TCP Keep-Alives (注意这是协议的解读站在协议的角度)
- TCP Keepalive 虽不是标准规范,但操作系统一旦实现,默认情况下须为关闭,可以被上层应用开启和关闭。
- TCP Keepalive必须在 没有任何数据(包括ACK包)接收之后的周期内才会被发送,允许配置,默认值不能够小于2个小时
- 不包含数据的ACK段在被TCP发送时没有可靠性保证,意即一旦发送,不确保一定发送成功。系统实现不能对任何特定探针包作死连接对待
- 规范建议keepalive保活包不应该包含数据,但也可以包含1个无意义的字节,比如0x0。
- SEG.SEQ = SND.NXT-1,即TCP保活探测报文序列号将前一个TCP报文序列号减1。SND.NXT = RCV.NXT,即下一次发送正常报文序号等于ACK序列号;总之保活报文不在窗口控制范围内 有一张图,可以很容易说明,但请仔细观察Tcp Keepalive部分:

TCP Keepalive 需要注意的点(协议层面)
- 不太好的TCP堆栈实现,可能会要求保活报文必须携带有1个字节的数据负载
- TCP Keepalive应该在服务器端启用,客户端不做任何改动;若单独在客户端启用,若客户端异常崩溃或出现连接故障,存在服务器无限期的为已打开的但已失效的文件描述符消耗资源的严重问题。
- 但在特殊的NFS文件系统环境下,需要客户端和服务器端都要启用Tcp Keepalive机制。
- TCP Keepalive不是TCP规范的一部分,有三点需要注意:
- 在短暂的故障期间,它们可能引起一个良好连接(good connection)被释放(dropped)
- 它们消费了不必要的宽带
- 在以数据包计费的互联网消费(额外)花费金钱
Tcp keepalive 如何使用
以下环境是在Linux服务器上进行,应用程序若想使用需要设置SO_KEEPALIVE套接口选项才能够生效。
系统内核参数配置
- tcp_keepalive_time,在TCP保活打开的情况下,最后一次数据交换到TCP发送第一个保活探测包的间隔,即允许的持续空闲时长,或者说每次正常发送心跳的周期,默认值为7200s(2h)。
- tcp_keepalive_probes 在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包次数,默认值为9(次)
- tcp_keepalive_intvl,在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包的发送频率,默认值为75s。
若设置,服务器在客户端连接空闲的时候,每90秒发送一次保活探测包到客户端,若没有及时收到客户端的TCP Keepalive ACK确认,将继续等待15秒*2=30秒。总之可以在90s+30s=120秒(两分钟)时间内可检测到连接失效与否。
以下改动,需要写入到/etc/sysctl.conf文件:
net.ipv4.tcp_keepalive_time=90 net.ipv4.tcp_keepalive_intvl=15 net.ipv4.tcp_keepalive_probes=2
保存退出,然后执行sysctl -p生效
可通过 sysctl -a | grep keepalive 命令检测一下是否已经生效。
TcpKeepLive常见的使用模式
默认情况下使用keepalive周期为2个小时,如不选择更改属于误用范畴,造成资源浪费:内核会为每一个连接都打开一个保活计时器,N个连接会打开N个保活计时器。
优势很明显:
- TCP协议层面保活探测机制,系统内核完全替上层应用自动给做好了
- 内核层面计时器相比上层应用,更为高效
- 上层应用只需要处理数据收发、连接异常通知即可
- 数据包将更为紧凑
关闭TCP的keepalive,完全使用业务层面心跳保活机制 完全应用掌管心跳,灵活和可控,比如每一个连接心跳周期的可根据需要减少或延长
业务心跳 + TCP keepalive一起使用,互相作为补充,但TCP保活探测周期和应用的心跳周期要协调,以互补方可,不能够差距过大,否则将达不到设想的效果。
朋友的公司所做IM平台业务心跳2-5分钟智能调整 + tcp keepalive 300秒,组合协作,据说效果也不错。
虽然说没有固定的模式可遵循,那么有以下原则可以参考:
- 不想折腾,那就弃用TCP Keepalive吧,完全依赖应用层心跳机制,灵活可控性强
- 除非可以很好把控TCP Keepalive机制,那就可以根据需要自由使用吧
TcpKeepLive 注意事项
我们知道TCP连接关闭时,需要连接的两端中的某一方发起关闭动作,如果某一方突然断电,另外一端是无法知道的。tcp的keep_alive就是用以检测异常的一种机制。
有三个参数:
- 发送心跳消息的间隔
- 未收到回复时,重试的时间间隔
- 重试的次数
如果是Linux操作系统,这三个值分别为
huangcheng@ubuntu:~$ cat /proc/sys/net/ipv4/tcp_keepalive_time 7200 huangcheng@ubuntu:~$ cat /proc/sys/net/ipv4/tcp_keepalive_intvl 75 huangcheng@ubuntu:~$ cat /proc/sys/net/ipv4/tcp_keepalive_probes 9
也就意味着每隔7200s(两个小时)发起一次keepalive的报文,如果没有回应,75秒后进行重试,最多重试9次即认为连接关闭。
这三个选项分别对应TCP_KEEPIDLE、TCP_KEEPINTL和TCP_KEEPCNT的选项值,通过setsockopt进行设置。
但是,tcp自己的keepalive有这样的一个bug:
**
正常情况下,连接的另一端主动调用colse关闭连接,tcp会通知,我们知道了该连接已经关闭。
但是如果tcp连接的另一端突然掉线,或者重启断电,这个时候我们并不知道网络已经关闭。
而此时,如果有发送数据失败,tcp会自动进行重传。
重传包的优先级高于keepalive,那就意味着,我们的keepalive总是不能发送出去。 而此时,我们也并不知道该连接已经出错而中断。在较长时间的重传失败之后,我们才会知道。
为了避免这种情况发生,我们要在tcp上层,自行控制。
对于此消息,记录发送时间和收到回应的时间。如果长时间没有回应,就可能是网络中断。如果长时间没有发送,就是说,长时间没有进行通信,可以自行发一个包,用于keepalive,以保持该连接的存在。
为什么有了keepalive还需要应用层心跳?
1、keepalive用来保持NAT网络路由表不被删除
2、keepalive只能表明服务器连接存在,但是服务器负载过高,探测不到
3、心跳用来检测实时在线,连接断开,心跳发送后马上就知道。
4、心跳在一些场景,比如实时在线游戏,必须马上知道掉线。