
Join在SQL是给两个或以上表建立连接的基本操作,本文以TenDB (开源MySQL分支) 为例,介绍Join算法的底层原理。
官方网址: https://tendbcluster.com
TSpider: https://github.com/Tencent/TenDBCluster-TSpider
TenDB: https://github.com/Tencent/TenDBCluster-TenDB
Tdbctl: https://github.com/Tencent/TenDBCluster-Tdbctl
单机Join — 以TenDB为例
以下面的表结构和数据为例:
CREATE TABLE t2 (id INT PRIMARY KEY AUTO_INCREMENT,a INT,b INT, # b是一个普通列KEY ka(a) # a上有个索引, id是主键)ENGINE=INNODB;# 插入数据 (1,1,1)到(1k,1k,1k)共1000条INSERT INTO t2 VALUES(1,1,1),(2,2,2),...,(1000,1000,1000);# t1与t2表结构相同,是t2的前100条数据CREATE TABLE t1 LIKE t2;INSERT INTO t1 (SELECT * FROM t2 WHERE id<=100);
Nested Loop Join
对于基于索引a的两表Join语句:
SELECT * FROM t1 straight_join t2 ON t1.a = t2.a;(在这里staright_join告诉了MySQL Server的执行器,必须按照t1 join t2的顺序执行,而不是反过来)
由于限制了执行顺序是t1 join t2,此时t1被称为驱动表,t2被称为被驱动表。
现在,使用Explain查询执行计划:

从Explain中可以看到,在Join过程中,t1采用了全表扫描,t2使用了在列a上的索引,整个的执行流程是
1. 从t1中取得一条数据R1;
2. 在t2的二级索引中匹配t1的a列;
3. 如果匹配成功,回表在t2的聚集索引中查找到相应的记录<S1>;
4. S1和R1组成一行<R1, S1>,加入结果集;
5. 重复执行步骤1,2,3,直到t1全表扫描结束。
整个过程如下图所示: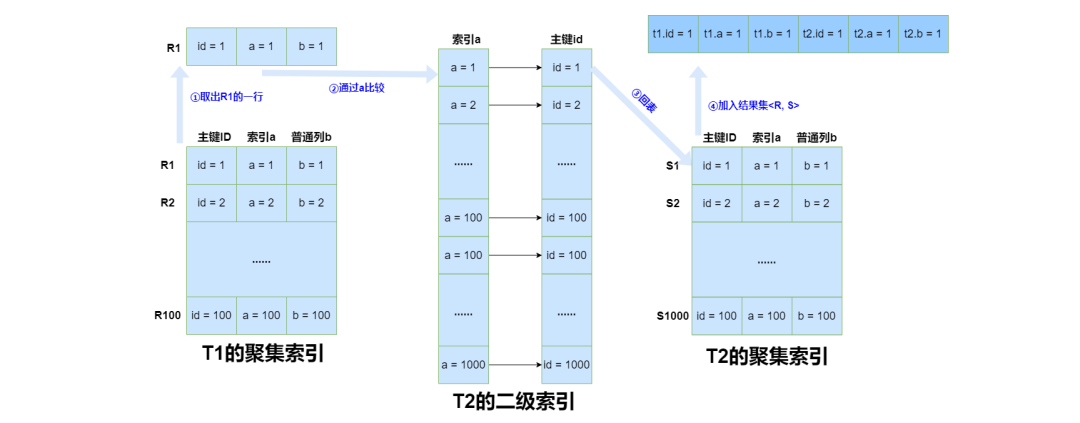
这个过程被叫做Nested Loop Join。在多表Join时,使用嵌套循环匹配,在最内层获得最终的结果,名字由此而来。上面被驱动表用了索引,所以被称作Index Nested Loop Join。
我们可以对它的时间复杂度进行估算。根据执行计划,驱动表走的是全表扫描,假设驱动表的行数为N;假设被驱动表行数为M,被驱动表进行B树搜索(InnoDB),可以近似它的搜索时间复杂度为logM。
那么整个的搜索时间复杂度就是驱动表的行数N乘上在被驱动表上匹配的复杂度logM,大约为NlogM。加上InnoDB的回表特性(要对复杂度乘2),以及最开始的对表t1的扫描N,整个的扫描行数为
2NlogM + N
可以看到N对扫描行数影响更大,所以尽量选择小表进行Join。
上面说的例子仅适用于可以用索引的情况。如果对于一个普通列进行Join,扫描行数就要多很多:
SELECT * FROM t1 straight_join t2 ON t1.a = t2.b;此时即使t1可以用a上的索引,但是t2上的b没有索引,在t1为驱动表时无法快速搜索,t2只能通过全表扫描的方式查找符合条件的列。这样的话,扫描的行数就是t1中的行数N + t1行数N × t1在t2中查找需要扫描的行数M,为
N + NM
根据之前的例子,需要100+1000×100,超过十万行。效率会大大降低。
Block Nested Loop Join (BNL)
对于这种Join,MySQL会利用Block缓存的思想,增加一个内存join_buffer,它缓存部分数据以使得匹配的行为发生在内存中,从而提升运行速度。算法的执行流程是:
1. 扫描表 t1,顺序读取数据行放入 join_buffer 中(由于这个语句是select *,所以会将整个t1内容放进内存);
2. 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
这种算法被称为Block Nested Loop Join (BNL)

由于用t1的记录被内存cache,t1匹配t2的十万次操作都是在内存中进行,提高了运行效率。
如果join_buffer不够大,不能够完全缓存t1的所有行数,假设每次只能缓存70行,MySQL会分两次,
1. 将t1前70行放入join buffer;
2. 用join_buffer中的行去匹配t2。匹配完成后返回部分结果;
3. 清空join buffer;
4. 重新将后30行放入;
5. 重复执行2,3直至t1所有行扫描完。
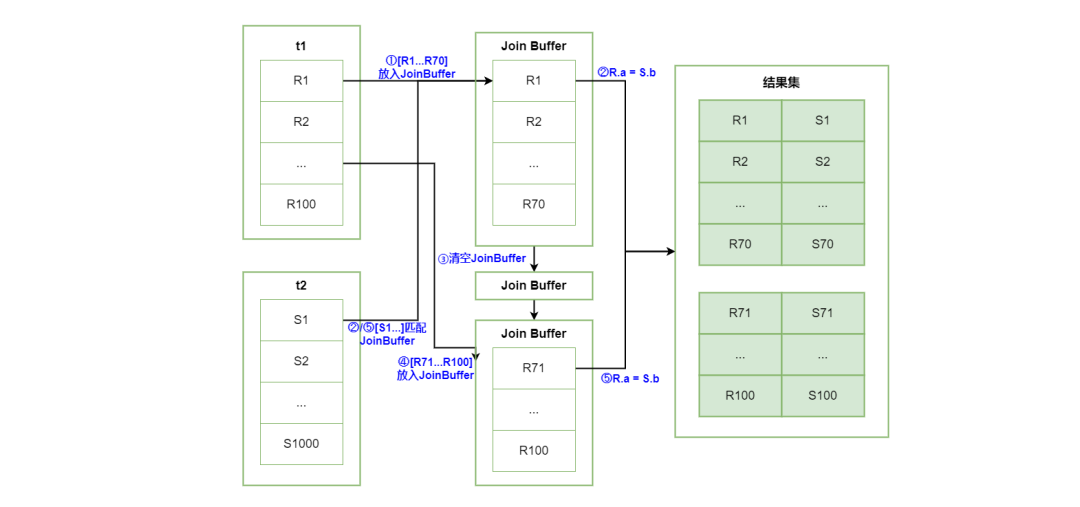
注:可以用参数 join_buffer_size 控制join_buffer可缓存的行数,以提升性能。在size不够大时,应该优先选择较小的表作为驱动表。
BNL的性能问题
上述的BNL算法在有一个驱动表是一个小表时表现良好,但是若两个表都很大,性能就会差很多。MySQL引入了Batch Key Access (BKA)算法来优化。
BKA算法的思想来源于执行计划Multi-Range Read的优化,下面先介绍Multi-Range Read的优化:
Multi-Range Read:
以下面的SQL为例:
EXPLAIN SELECT * FROM t1 WHERE a >= 10 AND a <= 15;常规情况下,InnoDB会先查询索引树,找到一个符合条件的a以后,获得对应的主键值,再对聚簇索引进行查找,然后再找下一个符合条件的a,并重复执行上面的步骤。这样会存在一个问题,如果随着 a 的值递增顺序查询的话,id 的值可能是随机的,访问聚簇索引时会出现随机访问,对磁盘访问不友好。
Multi-Range Read优化就是在获得(a, id)的索引集合后,对齐按照主键id进行排序,由于大多数数据是按照主键递增的顺序插入的,所以在最后回表时,会按照顺序访问磁盘,使得在HDD上性能提升明显。
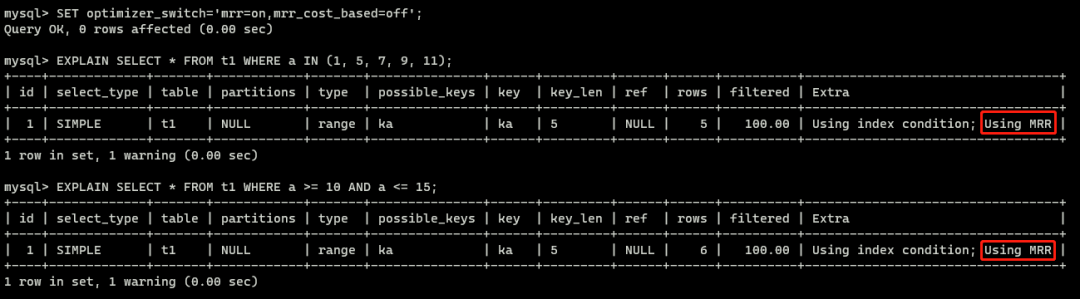
注意:如果想要使用MRR优化,需要:
SET optimizer_switch='mrr=on,mrr_cost_based=off';前者是打开MRR优化,后者让系统更倾向于使用MRR。如果后者打开,系统会通过代价计算来判断是否使用MRR,而MySQL对于MRR的代价估算是悲观的,导致很可能最后不会用MRR优化。
Batch Key Access Join (BKA)
BKA利用了MRR优化的思想,对于以下SQL(与最开始Index Nested Loop举例的SQL一样)
SELECT * FROM t1 straight_join t2 ON t1.a = t2.a;与BNL相同的是,BKA会先把t1的数据全部(Select *)放入Join Buffer;在此基础上,BKA将索引值a批量发送到MRR接口中,让MRR根据其主键进行排序,再批量地去t2中回表,使得回表时尽可能地顺序读。
值得注意的是,由于这里的SQL是SELECT *, 所以Join Buffer会缓存T1所有列的内容。如果这里只SELECT a,由于BKA需要根据RowID进行排序,所以Join Buffer不只会缓存列a,还需要缓存主键列id。

注意,如果需要用BKA算法,需要
SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
Incremental Join Buffers
在MariaDB中,有Incremental Join Buffer的概念。假设现在join涉及到三个表,按照
(t1 join t2) join t3
的顺序进行join。那么在BNL或BKA下,Join Buffer B1存放了t1里面的数据<r1>,B2存放了t1和t2中满足条件的数据<r1, r2>。此时B2就有两种存储方法。
一种方式是存放t1和t2 join结果集的一个副本<r1, r2>,也就是说将t1 join t2结果集的相关列深拷贝,保存到B2中,这种适合于r1占用的存储空间不大的情况。
但是可以发现,B2中的r1在B1中已经缓存了,并且这里的r1一定来自于B1中。于是第二种方式就是存放指向B1位置的指针和t2中的相关列<ptrB1, r2>。ptrB1指向Join Buffer1中对应的列,这样可以减少一部分内存重复拷贝。这种方式被称作Incremental Join Buffers。
Hash Join
MySQL 8引入了Hash Join的方法,对于t1 join t2,它会选择一个占用空间较小的表,在Join Buffer中建立一个Hash表(如果内存不够,会将部分数据写入磁盘),接着对大表进行全表扫描,用每一行数据跟Hash表中的数据进行匹配。
在理想情况下,Hash表中的匹配复杂度为常数级别,且又是内存操作,使得Join效率会大幅提升。
在分布式数据库系统中,多采用Hash Join,具体的实现方法有Broadcast Join / Shuffle Join。
参考文档
Block-Based Join Algorithms – MariaDB Knowledge Base
MySQL实战45讲_MySQL_数据库-极客时间
MySQL :: MySQL 5.7 Reference Manual :: 8.9.2 Switchable Optimizations